
„Никогаш не е доцна за кариерна промена“
По завршувањето на најзините студии на ФЕИТ, во областа на електроенергетика, Бојана Цубалевска одлучи да ги надогради своите вештини и знаења. За да ги исполни
Понеделник - Петок
Data Еngineer at Data Masters

Data Engineer at Data Masters
Во второто продолжение од серијата на текстови посветени на Data Engineering, детално ќе ја разгледаме темата за имплементација на Data Engineering во cloud средини. Претходно, дискутиравме за бенефитите од Data Engineering и како овој процес ја олеснува работата на компаниите, но имајќи во предвид дека многу компании ги чуваат податоците на cloud, важно е да се разгледа кои можности се отвораат при ваков тип на администрација на податоците.
Клучните процеси од Data Engineering вклучуваат целокупна администрација на податоците преку преземање на податоци од сите релевантни извори, трансформирање на собраните податоци за понатамошни анализи и креирање на целосно податочно складиште со оптимална архитектура. Дополнително, во зависност од локацијата и начинот на чување на податоците, на Data инженерите им е потребно да имаат познавања на администрација на податоци на локални складишта, како и на бази на податоци на cloud.
Денес, модерните технологии кои вклучуваат big data аналитики како и областите поврзани со вештачка интелигенција, имаат потреба од голема процесирачка моќ и скалабилни складишта. Во таа насока, cloud computing на компаниите им овозможува скалабилна алтернатива, споредено со локалните инфраструктури што се ограничени во овој поглед.
Dell reports that companies that invest in big data, cloud, mobility, and security enjoy up to 53% faster revenue growth than their competitors.
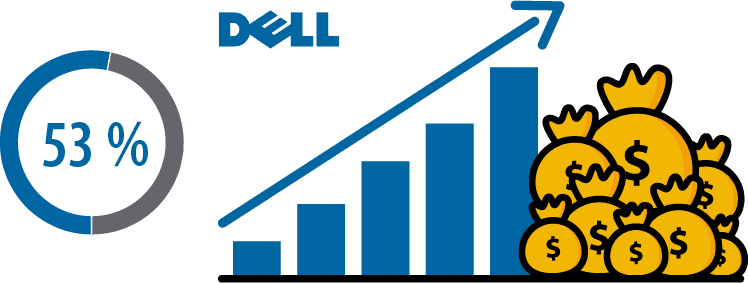
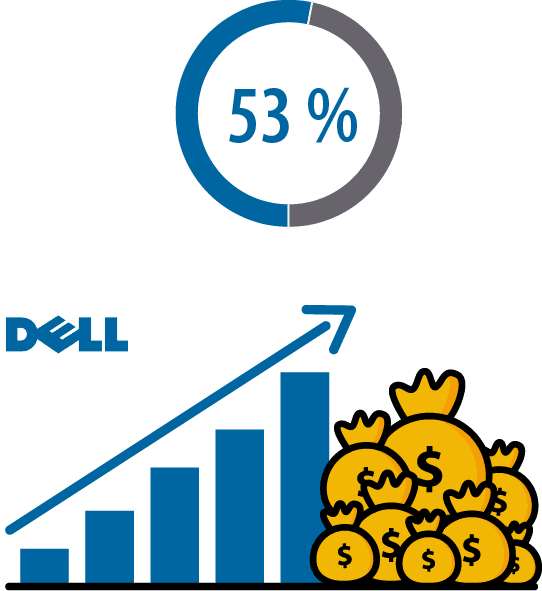
Истражувањата на Dell покажуваат дека компаниите кои инвестираат во Big Data, Cloud Computing, мобилност и безбедност имаат 53 отсто побрз раст на приходите во споредба со нивните конкуренти. Cloud сервисите како Amazon Web Services (AWS), Google Cloud Platform и Azure Cloud Services се најпопуларни и наоѓаат широка примена кај компаниите ширум светот. Tие овозможуваат многу различни on-demand сервиси, скалабилност и еластичност, лесно одржување, безбедност, автоматизација и флексибилност.
Amazon Web Services (AWS) е една од водечките cloud платформи на глобално ниво која нуди повеќе од 200 различни сервиси кои можат да ги исполнат сите можни барања на нивните клиенти. Поради големиот број на сервиси кои ги овозможува во различни домени, AWS нуди целосна поддршка на компаниите за комплетен cloud computing и сите поврзани бизнис процеси. За потребите на Data Engineering, оваа платформа нуди пет различни видови на сервиси, и тоа:



Процесот на собирање на податоци е еден од клучните процеси во Data Engineering. Во оваа фаза се собираат сирови податоци од хетерогени извори, вклучувајќи различни бази на податоци, мобилни уреди, сензори и многу други извори. Целта е создавање на податочно езеро кое ќе ги содржи сите релевантни податоци на една компанија. За да се соберат податоците од сите различни извори, AWS ги вклучува сервисите на Amazon Kinesis Firehose, AWS Snowball и AWS Storage Gateway.
Користењето на Amazon Kinesis Firehose овозможува директно пренесување на податоци до складиштето во реално време. Дополнително, со оваа алатка податоците може да се трансформираат пред да се складираат, како и да се енкриптираат и компресираат.
Доколку податоците на клиентите се складирани во локални бази на податоци, за нивна репликација на cloud може да се искористи сервисот AWS Snowball.
Во случаи кога е потребно надополнување на податоците на дневно ниво, додека тие се потребни за работа и на локално ниво, тогаш се користи AWS Storage Gateway.

По процесот на преземање на податоците, потребно е тие да се складираат во податочни езера. Овие сервиси нудат различни решенија во зависност од типот на податоци и начинот на кои тие се преземаат и искористуваат. Во однос на сервисите за складирање, доминира сервисот Amazon S3.
Овој сервис овозможува градење на податочни езера и складирање на големи количини податоци во различни форми. Станува збор за многу скалабилно и брзо решение преку кое податоците од различни извори се вклопуваат во податочно езеро кое e логички поделено на Buckets и Folders. Amazon S3 има целосна интеграција со останатите AWS сервиси за да се овозможи непрекинат тек на податоците меѓу сервисите.

Уште еден важен аспект на Data Engineering е и интерграцијата на достапните податоци. Во суштина, сервисите за интеграција на податоци ги комбинираат податоците од различни извори преку централизираниот процес ETL (Extract – Transform – Load). Во овој процес се анализираат различните извори на податоци, се преземаат и се трансформираат потребните податоци за да се генерираат соодветни шеми за нивно користење.
Во склоп на алатките за интеграција на податоци, клучнo e користењето на сервисот AWS Glue. Овој сервис овозможува собирање на податоци од различни извори и спроведување на трансформации на истите. По трансформацијата на податоците, се генерира шема на податоците која ги опишува сите ентитети, атрибути и податочни типови, за да се наполни податочното езеро или складиште. AWS Glue е моќен сервис кој нуди многу функционалности за преземање на податоците и нивно трансформирање, за да се добие стандардизирана шема на податоците. Во склоп на овој сервис е вклучен и Data Catalog, кој претставува централизирано место за сите мета-податоци.
Функционалностите на AWS Glue можеме да ги сумираме на следниот начин: трансформација и преземање на податоци преку Glue Jobs, генерирање на стандардизирана шема преку Crawler и преку генерираниот Data Catalog креирање на база на податоци со соодветни табели.

Сервисите за градење на податочни складишта овозможуваат генерирање на репозиториум на структурирани податоци од различни извори. Важно е да се напомене дека разликата на овие алатки во однос на Amazon S3 е во тоа што податочните езера собираат сирови податоци во оригинална форма за генерална употреба. За разлика на тоа, во податочните складишта се складираат податоци за специфична намена, каде податоците имаат стандардизирана шема за оптимизација при нивно искористување.
Amazon Redshift е решение кое нуди петабајтно складиште на податоци за структурирани и полуструктурирани форми на податоци. Овој сервис користи стандардизирана шема на податоците, за оптимизирано искористување при Business Intelligence анализи. Преку AWS Glue се преземаат транформираните податоци од Amazon S3 и се вчитуваат во Amazon Redshift за понатамошно паралелно процесирање на големи количини на податоци.

Сервисите за оваа намена содржат Business Intelligence алатки, кои имаат за цел да ги визуелизираат податоците за понатамошна примена. Во суштина, сите податоци од податочните складишта и податочните езера се влезни информации во овие сервиси од кои се генерираат извештаи, графикони и се добива генерален поглед кон податоците.
Од спектарот на сервиси на AWS, Amazon QuickSight претставува алатка преку која лесно се генерираат BI Dashboards. Овој сервис може да се користи на различни уреди преку опцијата за вградување на извештаите и графиконите во веб апликации и портали. Дополнително, треба да се напомене дека при Data Engineering на AWS, важна е и интеграцијата на Amazon Redshift со многу други Business Intelligence и Business Analytics алатки.
Компаниите честопати имаат податоци во различни форми и од различни извори, од кои понатаму е потребно да се извлечат клучни факти и информации вредни за бизнисот. Таков пример е една клиентска компанија на Data Masters, чиј case study можете да го прочитате тука.
Станува збор за компанија која прима големи количини податоци на дневно ниво од шест различни извори. Компанијата се соочува со губење на податоци поради несоодветно справување со нив и добива неконзистентни и неточни информации за своите модели на вештачка интелигенција. За да се креира решение, нашиот тим одлучи да ја искорсти cloud платформата AWS, земајќи го во предвид тоа што клиентите користат AWS сервиси за своите потреби.
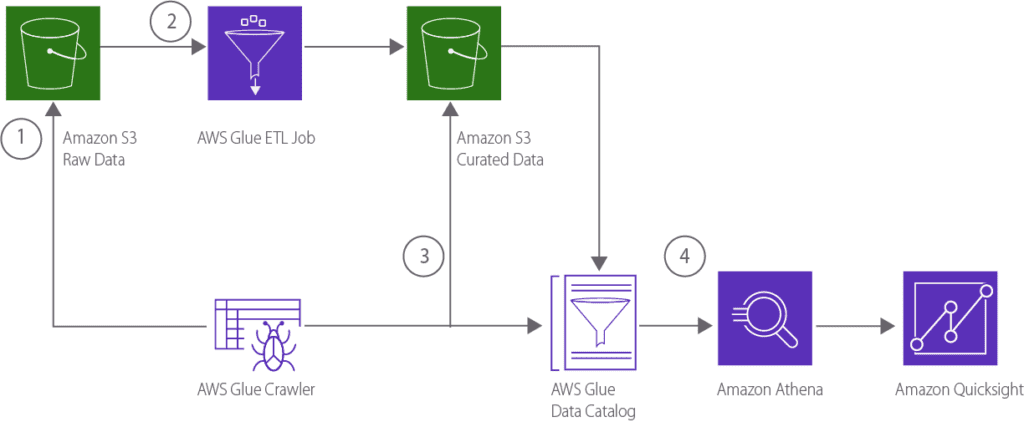
Во првата фаза, потребно беше да се разграничи разновидноста на изворите на податоците. Процесот започна со преземање на податоци од локални бази и добивање на податоци од различни системи, кои автоматски ги зачувуваат податоците во Amazon S3. Со оглед на различните извори и типови на податоци, креиравме хиреархија на чување на сировите податоци во Amazon S3. Но, во овој конкретен случај се соочивме со следниот проблем – сировите податоци беа во различни формати и подложеа на различна грануларност.
Поради потребата за стандардизирани шеми на податоци, се одлучивме да го користиме сервисот AWS Glue. Користењето на овој сервис, покрај можноста за трансформирање на податоците, овозможува и директно преземање на податоци од локални бази на податоци на клиентот.
Во втората фаза на преземање и трансформирање на податоците, го користевме сервисот AWS Glue. Во склоп на овој сервис се достапни Glue Jobs, кои се скрипти напишани во Spark или Python. Со користење на овие скрипти, овозможивме пристап до локална база од која извлекувавме податоци кои се зачувуваат во Amazon S3. Други скрипти беа искористени за преземање на податоците од Amazon S3, истите се трансформираа користејќи Python Data Frames и потоа се зачувуваа како партиционирани фајлови. Во овој чекор важно е партиционирањето на податоците, поради оптимизација на читање на податоците. Од трансформираните податоци се генерираа табели во склоп на сервисот, за кои автоматски се генерира шема користејќи ја функционалноста Glue Crawler.
Во следната фаза, веќе имаме креирано партиционирани табели на податоци и потребно е тие соодветно да се искористат преку пишување на SQL изрази кое го овозможува сервисот Amazon Athena. Овој сервис е интегриран со табелите креирани во AWS Glue кој може да ги толкува соодветните изрази. Во овој случај, за оптимизирано и брзо пристапување на податоците, се генерираше база на податоци користејќи ја Data Vault методологијата. За таа цел се користеше сервисот Amazon Athena во кој преку SQL скрипти ја генериравме структурата на базата, користејќи податоци од табелите генерирани во претходниот чекор. Преку оваа методологија овозможивме логичка поделба на податоците и избегнување на редундантни податоци во архитектурата.
Со следење на овие чекори генериравме Data Vault преку преземање на податоци од различни извори и нивна соодветна трансформација. Иако можеби досегашниот процес изгледа многу комплексно, тој може да се автоматизира преку сервисот AWS Step Functions, што ја олеснува работата на девелоперот.
Решението кое го изградивме, користејќи ги спомнатите сервиси на AWS, му овозможи на клиентот оптимално користење на своите податоци. Data Vault методологијата придонесе за подобри резултати при работата на клиентот, искористување помалку ресурси за складирање на податоците и заштеда на средства од буџетот.
Администрацијата на податоци покрај соодветното складирање, овозможува и оптимизиран пристап и извлекување клучни бизнис вредности за компаниите. Земајќи во предвид дека на дневно ниво се генерираат огромни количини на податоци, нивната манипулација преку cloud платформите е круцијална.
Data Engineering на cloud овозможува скалабилна администрација на големи количества на податоци користејќи ги предностите на сервисите достапни на cloud платформите. Како што е наведено во примерот, користејќи само неколку достапни cloud сервиси овозможува креирање на целосен проток на податоците без потреба од менаџирање на самото складиште (и без потреба од дополнителни калкулации). Од правилното справување со достапните податоци произлегуваат позитивни резултати, нови сознанија и бенефити за самата компанија со помош на Data Engineering на cloud.
По завршувањето на најзините студии на ФЕИТ, во областа на електроенергетика, Бојана Цубалевска одлучи да ги надогради своите вештини и знаења. За да ги исполни

Дознај како да станеш Data Analyst и откри ги клучните чекори за трансформација на твојата кариера, вклучувајќи ги сите вештини што ти требаат. Доколку ја

Имавме чест и задоволство да разговараме со Алекандра Павлеска Ѓорѓијоска, Data Analyst во Македонски Телеком, која беше учесник на обуката Data Analytics for Business Decision
По завршувањето на најзините студии на ФЕИТ, во областа на електроенергетика, Бојана Цубалевска одлучи да ги надогради своите вештини и знаења. За да ги исполни
Дознај како да станеш Data Analyst и откри ги клучните чекори за трансформација на твојата кариера, вклучувајќи ги сите вештини што ти требаат. Доколку ја
Имавме чест и задоволство да разговараме со Алекандра Павлеска Ѓорѓијоска, Data Analyst во Македонски Телеком, која беше учесник на обуката Data Analytics for Business Decision

И покрај сите дискусии за тоа колку сознанијата од податоците можат да влијаат на профитабилноста на една компанија, повеќето организации сè уште заостануваат во имплементација

Веб-страницата academy.datamasters.ai користи различни типови на колачиња кои се неопходни за правилно функционирање на веб-страната, подобрување на корисничкото искуство и за сите наведени цели во политиката за колачиња. Повеќе информации овде.